

Most Successful Agile Experience
Tools, Culture, People & Processes

Executive technology leader responsible for platform reliability, cloud operations, security posture, and enterprise technology risk within an investor-backed fintech environment. I lead technology operations at the intersection of engineering execution, governance, and business outcomes — ensuring platforms are scalable, resilient, and trusted by investors, regulators, and clients.
Currently VP of DevOps at InvestorFlow, where I focus on building board-ready technology operations, strengthening risk and resilience, and shaping long-term platform strategy to support growth and regulatory confidence.
It's one experience I always refer to when providing examples of agile success in software development. The collaboration, processes, culture, people and tools fit so well, making the experience seamless and feeling good to work at.
In this post, I am sharing critical high-level facts on how I experienced what I describe as the most successful agile team. It wasn't like this when I first started; it was the complete opposite, but I and other thought leaders came together to make multiple teams become a single collaborative software development and product delivery team.
Four core areas resulted in the success I saw. These were Culture, People, Processes and Tools. Missing out any of these core areas would have resulted in a bad result. I am not saying this is perfect; nothing is perfect and requires improvement.
Culture
A no-blame culture was adopted during retrospectives. This enabled continuous improvement of our processes and people across multiple teams. When retrospectives start, a reminder that we are working on a no-blame culture is very effective. I found that more people submitted written and verbal improvements if reminded of this.
Engineering was encouraged to be autonomous. To do this, engineers wrote, reviewed and maintained an engineering handbook. The handbook was visible publicly for accountability purposes and to share what we learned with the broader community. The handbook contained a team charter, processes we had implemented, and coding practices we adhered to. Information on this can be found in Andrew Urwin's blog post.
Continuous improvement was significant across our teams. This was achieved by collaborating, sharing ideas, and making changes when we know something isn't working. Feedback was an incredible driver to most of our improvement, learning from the engineers and product team if something was not working for them.
People
Collaboration is necessary across all parties. The throwing-over-the-wall method is proven to be less effective and causes friction between teams. As such, DevOps, QA, Engineering and Product participation is necessary throughout the sprint cycle. It may not require everyone from each team to be at every phase, but a representative is essential.
Change is essential to improving how we work. If we do not change, then we are likely to fail. We need people to be open and willing to accept changes. I found this to be a challenge in nearly every work setting, but I do find that taking feedback and sharing any concerns with the broader team enabled changes to be accepted and adopted much quicker.
To accept change, you must be open-minded. We asked people to be open-minded to new ideas, try new things, and then come to a conclusion. It is also a requirement for people to be truthful about changes. If something is wrong, we as a team need to know to find a solution.
Sharing of ideas was another attribute we asked people to participate in. Encouraging idea submissions among peers in meetings or privately with leadership via instant messaging or a quick video call. One person should not make a judgment call on an idea that should be shared, even if the person submitting it wants to be anonymous.
One person cannot be driving this for culture and people to succeed. It requires thought leaders to continuously encourage the way of working, pushing their peers and leadership if we are falling short on any values.
Processes / Practices
Sprints
Sprints were two weeks long, starting on a Monday. Even though work items were allocated at the start of the sprint, new items can be brought into the sprint as and when required. Release of sprint items can be done when ready and did not have to wait till the end of the sprint. Shorter sprints would occur due to public holidays, but we never extended a sprint for this or any other reason.
Daily Standups
Daily standups would be ten minutes long every day, no longer. For an effective daily standup, we asked people to make sure at the end of a working day to update their assigned work tasks with a comment on progress or any status fields. Five minutes before any standup, we asked engineers to read through the sprint work items comments that they are dependent on or working in collaboration with. During the ten-minute standup, the sprint board is shared in the meeting, and each person is asked:
What they did yesterday
What they are doing today
Are there any blockers
Whoever is leading the standup must ensure we stick to ten minutes.
Standup Leads
Standup leads are different daily and are assigned at the end of every sprint retrospective. Using a randomiser, an engineer is assigned a day of the week to be the standup lead. For example, John is assigned Mondays on the randomiser, which means they are leading the daily standups twice (both Mondays) in a sprint.
No one can avoid being a standup lead only if the randomiser doesn't choose them. This type of practice enables:
Focus during a standup
Identify leadership qualities
Build peoples voices
Retrospectives
Retrospectives (retros) were scheduled for the last day of the sprint, but the retrospective board is open at the start of the sprint, allowing individuals to add talking points easily. Retros would last one hour and would contain the following items to discuss from the board:
Previous retro actions update
What went well
What needs improving (didn't go well)
Actions from this retro
Five minutes would be allowed to add any additional retro item, reminding everyone that this is a no-blame culture, so be honest. We would then ask each contributor to speak about the item they added to the board. Once the contributor finished speaking, we open the floor to comments/feedback. This would sometimes result in actions that would then be allocated for individuals to complete by the following retro.
Sprint Pointing
Using planning poker to point base our items, we used the Fibonacci sequence to estimate. Once a work item has been refined in a refinement session, the team would individually score the work item using a tool (identified in the post later), which would allow us to hide the scoring until ready to reveal and then let us all collaboratively discuss any significant differences in the scoring.
Sprint Burndown
You cannot just implement sprint pointing and not burndown. Sprint burndown is a powerful visualisation among teams to work towards 0 points remaining at the end of the sprint. The visualisation allows leadership to identify causes for sprints to have outstanding items, for example, if something was brought into a sprint that affects the initial scope of the sprint. Tools discussed later in the post enable this visualisation and other detailed metrics.
Sprint Review
Sprint review should involve engineering, product and stakeholders to review the outputs/outcomes of the sprint. This was organised on the last day of the sprint, before the retrospective. During sprint review, we would demo any new features and gather any feedback we can use to improve with future changes. All sprint reviews were recorded and shared with anyone who couldn't attend.
Sprint Refinement
Refinements would occur at least once a week for approximately an hour and involve the whole engineering team and a representative from the product and QA teams. This would allow for refining items in the backlog by doing the following:
Breakdown work items into small actionable pieces that can be completed within a sprint window
Identify if something requires an architecture session due to the scale of work required
If a work item requires additional information, the product team should provide this outside of refinement or contact stakeholders.
Identify teams required to action items
Identify QA testing requirements
Story point the work items
Only urgent bugs would be allowed into a sprint without refinement. Anything else could not go into a sprint without a refinement session.
Tools
Jira Board

Jira was used for the backlog of product features/bugs. When a sprint is created, a board is available for live viewing of the swimlanes. Each swimlane represents the status of the work item. We used the following statuses for our work items:
Backlog - A work item yet to have work started
Blocked - A work item where work started but cannot proceed further due to something else stopping it
In Progress - A work item is currently being worked on
QA Ready - A work item is ready to be tested by QA based on the scope of work
Done (dev) - A work item has completed development
Done (released) - A work item has been released into the production environment
Jira Dashboards
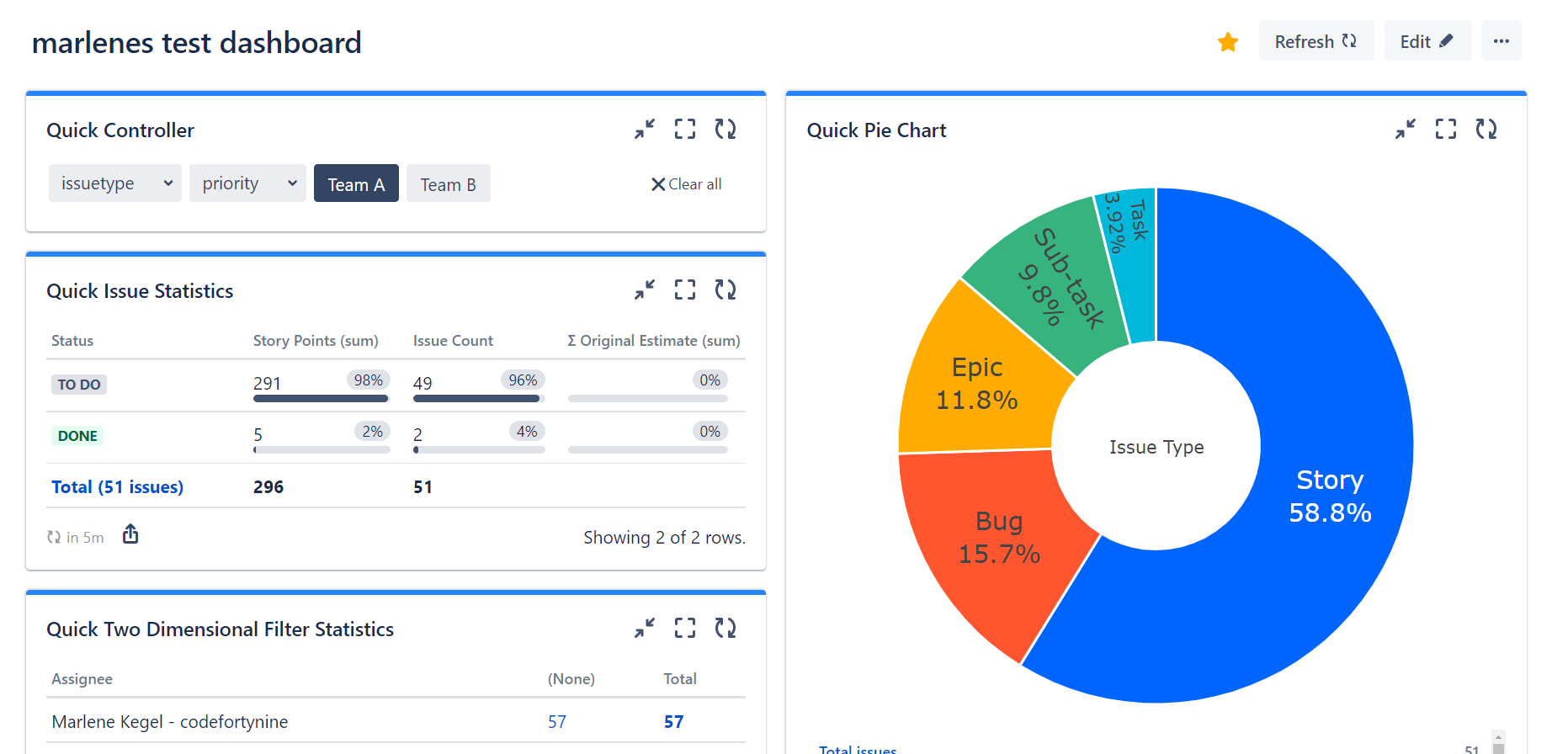
We used Jira dashboards for two purposes:
Live metrics of the current sprint progress. Burndown charts, days remaining, work items brought into a sprint after the start date, etc...
Work items ready to be released or have been released, containing dates and times
Dashboards gave us a quick and refined view of key metrics we used to monitor and manage our sprints.
Reetro.io
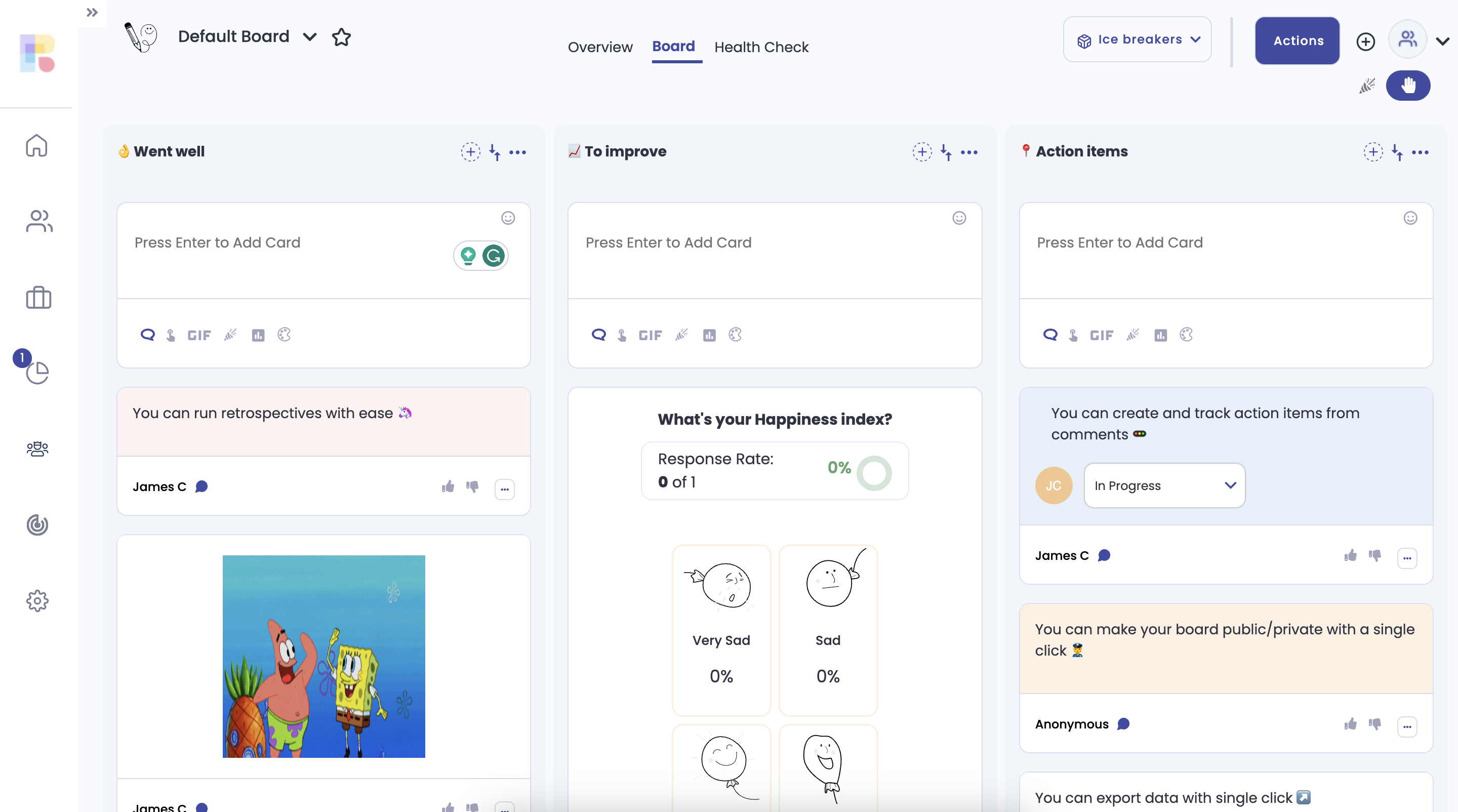
Reetro.io was used to give the team a collaborative board for retrospective items. We had swimlanes set up to gather feedback on a sprint, good and bad, as well as actions to take away from the retro. Each item submitted by a user could be upvoted on or commented on by peers.
Planning Poker
The planning poker feature in Jira allowed remote workers to story point items using this tool. The tool would visualise previous items that were story-pointed to help engineers compare the item they are scoring against ones scored previously. Once the item is scored, you can apply it immediately to the item without leaving the tool.
Spin the wheel
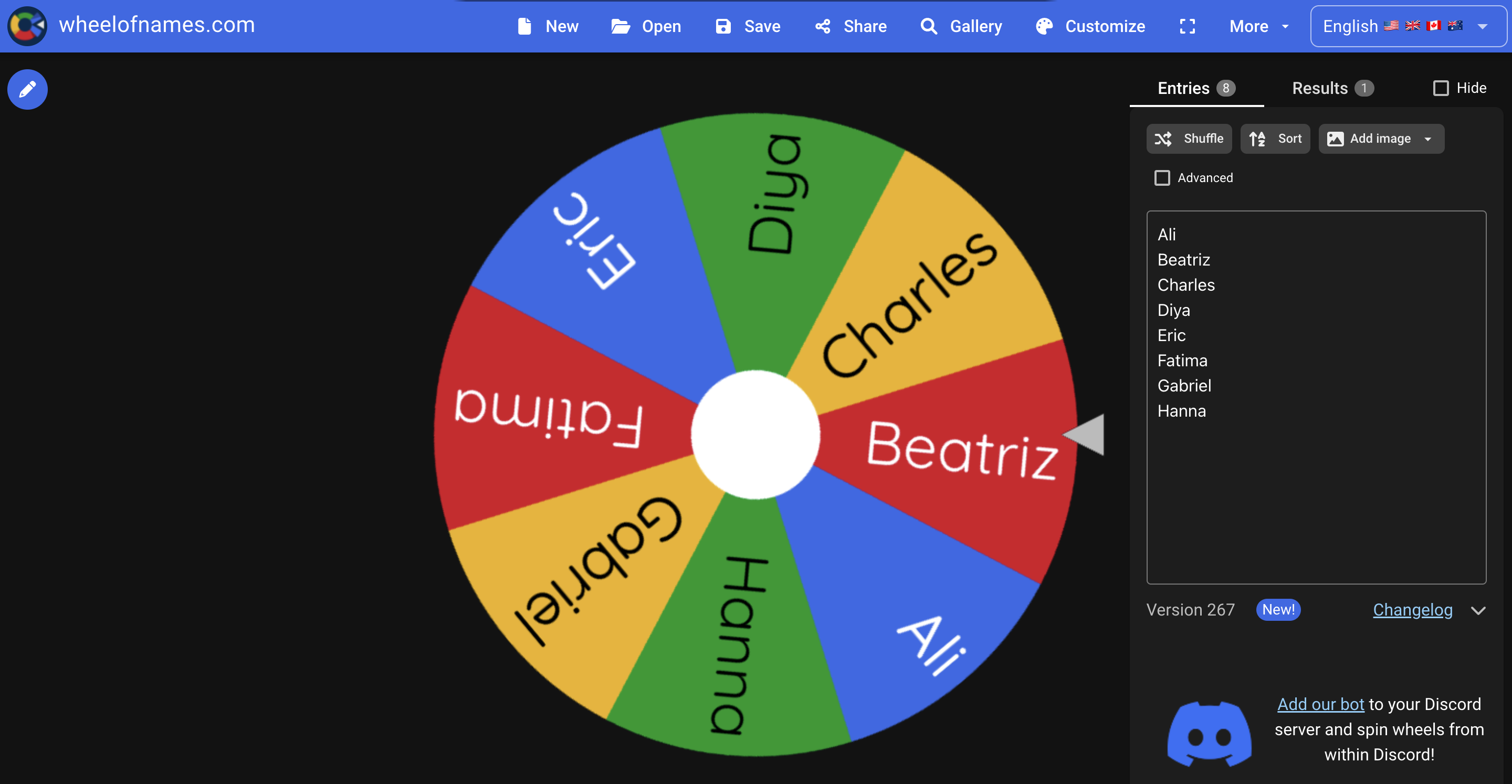
The spin-the-wheel tool would contain each engineer's name on it. We would then spin it each day of the week to allocate an engineer as standup lead. This would be done once at the end of the retrospective, and the engineer would then be responsible for standup that day.
Usehaystack.io
We found the data between the DevOps and project management tools compelling. Using usehaystack.io connected the two for us, and we were able to identify the following:
Cycle time history
Trends
Potential burnouts
High review times
High response times
Rework percentage
PR review time
PR approval time
Average throughput
Merge/Close rate
As well as these metrics, it would provide reports and alerts so we can act upon them and add to our process to improve.



